Frontier model training has consolidated into a small set of operators with the capital to assemble tightly-coupled GPU clusters. That concentration produces the fastest path to capability, but it also limits the decisions about what gets trained, on what data, and on what terms to those same operators.
For workloads that prioritize censorship-resistance or sovereign infrastructure, teams require frontier-level models that are structurally open. However, existing open-weight releases like LLama or Mistral are only open at the discretion of the sponsor.
Over the past 2 years, a few teams have experimented with a decentralized alternative: global AI-model training, coordinated across heterogeneous hardware and rewarded through a network.
Of those teams, Prime Intellect is among the furthest along, having publicly released multiple artifacts: the training framework (PRIME), the RL stack (PRIME-RL), the inference verifier (TOPLOC), and the resulting weights.
What Prime Intellect is building
Prime Intellect is building a single network where any participant can rent GPUs for inference, contribute compute to community-trained models in exchange for a share of ownership, or crowdsource compute for their own training runs. Think Hugging Face combined with a shared-ownership layer.
The team raised $15 million in February 2025, led by Founders Fund, bringing total funding north of $20 million. The round included Menlo Ventures alongside angels including Andrej Karpathy, Hugging Face’s Clem Delangue, SemiAnalysis’s Dylan Patel, Together AI’s Tri Dao, Balaji Srinivasan, and Stability’s Emad Mostaque.
The team built its infrastructure by training real models in public. To date, three artifacts have been produced:
- INTELLECT-1 — a 10B-parameter model based on the Llama-3 architecture, trained across five countries on three continents during a closed testnet run. The exercise was less about the resulting model and more about pressure-testing PRIME, the team’s distributed training framework, under realistic network conditions.
- SYNTHETIC-1 — a synthetic dataset of 1.4 million verified math, coding, and science tasks. The dataset is the input to the team’s own RL post-training work and is published as an open resource for other teams building reasoning models.
- INTELLECT-2 — a 32B reasoning model post-trained on QwQ-32B, using methods adapted from DeepSeek’s published RL pipeline. INTELLECT-2 is, to date, the largest model post-trained via a fully asynchronous, globally distributed RL framework.
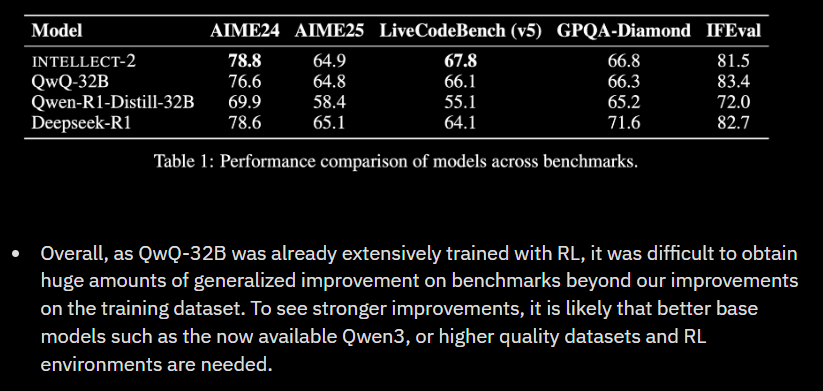
Each release has been accompanied by open-source components including training frameworks, verification tools, and dataset generation libraries that makeup the broader stack that the network is meant to run on.
The coordination layer: PRIME and OpenDiLoCo
PRIME is the distributed training framework that handles cross-node communication. The fundamental constraint it has to address is bandwidth. Synchronous training on a tightly-coupled cluster works because nodes are sitting on the same fabric. Centralized setups allow gradients to move at NVLink or InfiniBand speeds, and the all-reduce step is cheap relative to the compute. However, when the same workload is moved onto consumer-grade internet links spanning continents the all-reduce becomes the dominant cost.
PRIME adopts the OpenDiLoCo algorithm to address this. Rather than synchronizing gradients every step, each node trains largely independently and only exchanges updates with the rest of the network every 500 steps. The reported result is a roughly 2,000x reduction in bandwidth requirements relative to standard data-parallel training.
The second coordination problem is node churn. Distributed networks often lose connection to nodes when a participant’s machine reboots, their connection drops, or they exit voluntarily. ElasticDeviceMesh is the abstraction PRIME uses to handle this gracefully. When participants come and go, the active compute pool resizes rather than halting or rolling back the run.
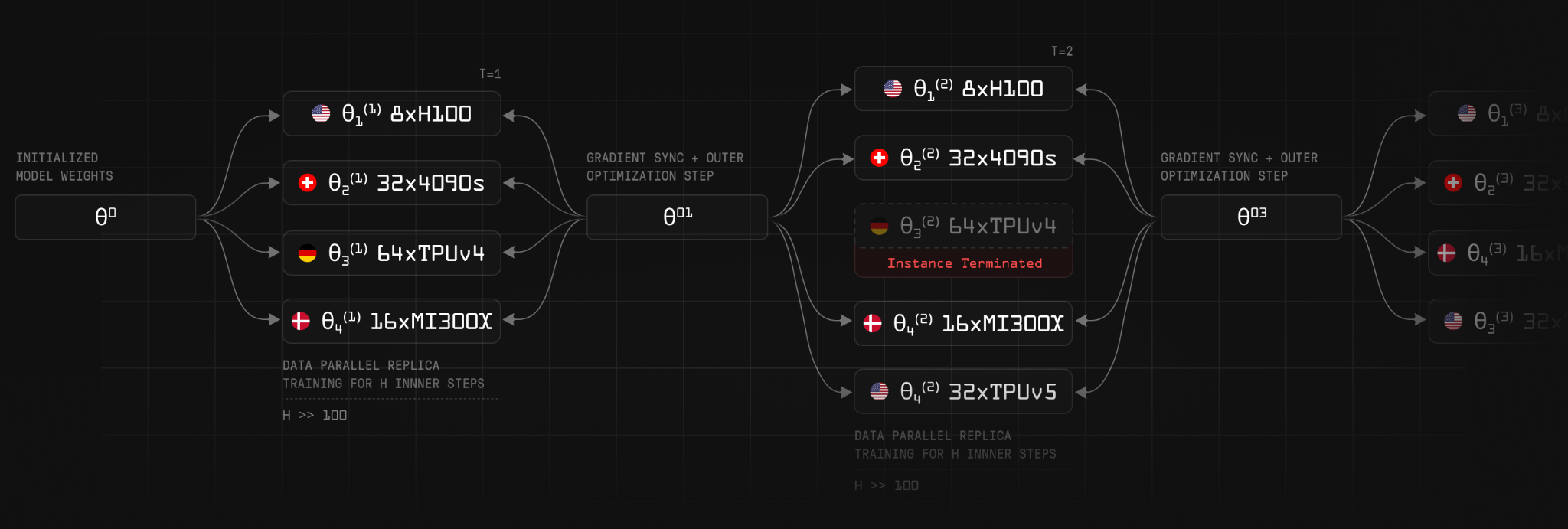
Post-training and reinforcement learning at scale
Reasoning models (e.g. GPT-o3 and DeepSeek-R1) are produced through a combination of supervised fine-tuning on step-by-step reasoning traces and reinforcement learning that rewards correct answers. INTELLECT-2 was Prime Intellect’s attempt to run the RL stage in a fully decentralized configuration.
To do this, the team built PRIME-RL, an extension of PRIME for distributed reinforcement learning. PRIME-RL splits the work across three roles:
- Inference rollout workers — distributed nodes that generate reasoning rollouts using the latest policy and compute their associated rewards.
- TOPLOC validators — verify that rollouts were generated honestly and according to the protocol.
- GRPO training workers — apply DeepSeek’s Group Relative Policy Optimization algorithm to update the model from the validated rollouts.
RL is naturally well-suited to asynchronous training because experience collection and policy updates can be decoupled. Rollout workers can keep producing trajectories while a central learner updates the policy.
Verification: TOPLOC
A network that pays anonymous participants for compute requires a verification layer. Otherwise irrational actors can submit fabricated outputs and collect rewards.
TOPLOC is Prime Intellect’s inference-verification scheme. It allows validators to confirm that a rollout was produced by the claimed model, on the claimed input, without re-running the full inference. Verification standards are maintained across heterogeneous hardware, GPU types, and computational reorderings.
Most cryptographic verification schemes for ML inference impose overheads that make them economically unworkable at training scale. However, TOPLOC verified rollouts during INTELLECT-2’s RL stage without introducing meaningful training-throughput penalties.
The settlement layer
The network only becomes a network when contributions can be measured and rewarded, and ownership of the resulting models can be assigned to the parties that produced them.
Prime Intellect uses a blockchain to handle accounting, reward distribution, and the issuance of the network’s token, which represents both governance and a claim on shared model ownership. The protocol is currently a testnet on Base network, with plans to migrate to a dedicated network in the future.
A public blockchain allows participants to enter and exit without a credentialing process, makes reward distribution algorithmically auditable, and provides a settlement primitive for whatever pricing mechanism the network ultimately adopts for compute and inference.
Competitors
Prime Intellect is one of several teams pursuing this design space. Competing projects include:
- Ambient — pre-testnet.
- Pluralis — pre-testnet.
- Gensyn — on testnet; an RL Swarm is currently live with additional features in development.
- Nous Research — Psyche network in development; an RL environment is live on testnet.
- Templar — live on Bittensor mainnet (subnet 3), pre-training a 1.2B-parameter model with plans to scale.
- Macrocosmos — live on Bittensor mainnet (subnets 9 and 37, focused on pre-training and post-training respectively).
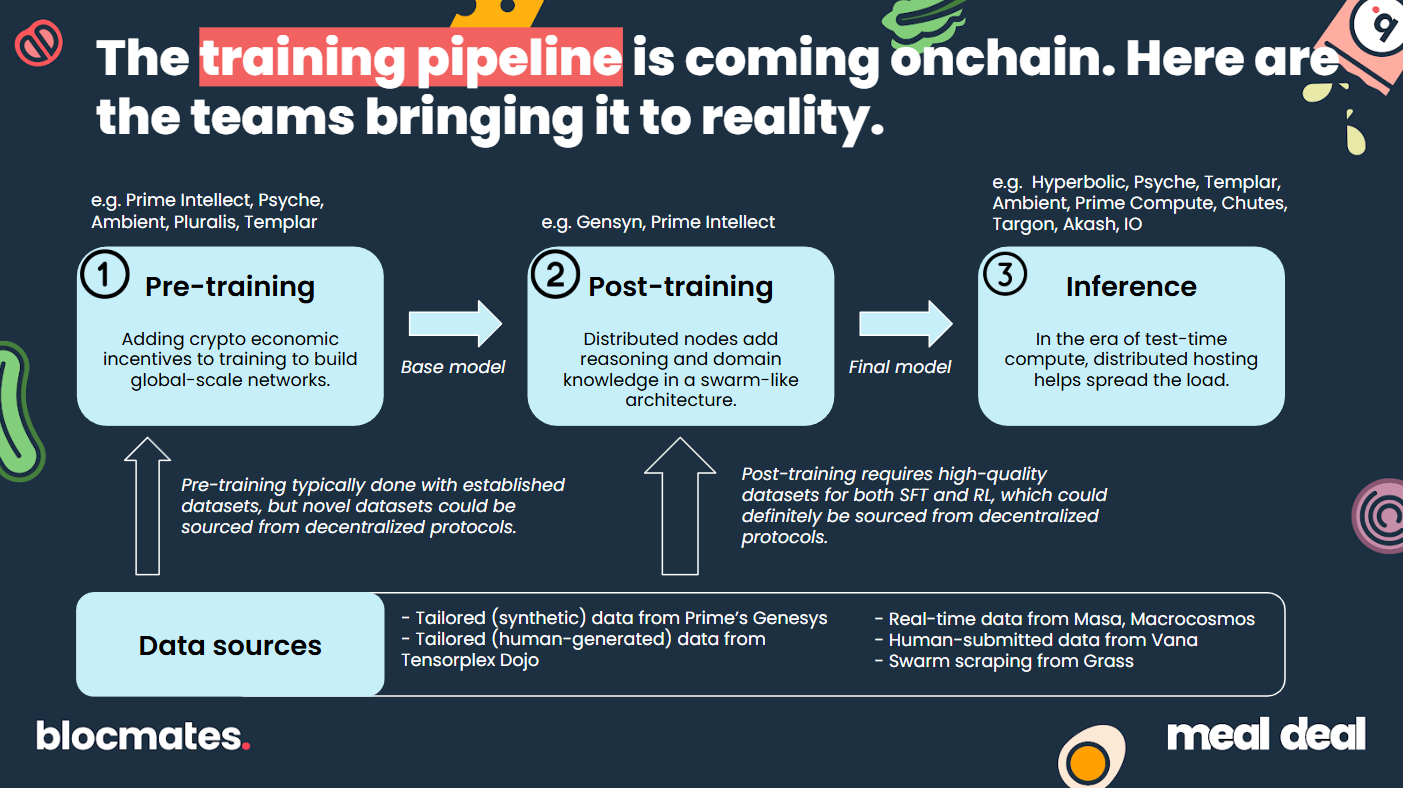
By development stage, the Bittensor subnets and Prime Intellect are furthest along. The Bittensor projects benefit from running on an established subnet economy with existing token incentives. On the other hand, Prime Intellect is operating independent infrastructure with its own coordination, verification, and incentive layers being built in parallel.
| Platform | Pre-training | Post-training | Inference |
|---|---|---|---|
| Prime Intellect | ✓ | ✓ | ✓ |
| Psyche | ✓ | ✓ | |
| Ambient | ✓ | ✓ | |
| Pluralis | ✓ | ||
| Templar | ✓ | ✓ | |
| Chutes | ✓ | ||
| Targon | ✓ | ||
| Akash | ✓ | ||
| IO | ✓ |
Conclusion
Prime Intellect’s distinguishing choice has been to build coordination, verification, and incentives as one integrated system rather than slot into an existing subnet economy. Yet distributed training only matters if the coordination layer can move gradients across the public internet without destroying the economics.
Thus, three open questions structure the next 12-18 months for this category.
First, can the network attract sustained, paid contribution at scale? Training runs to date have drawn around twenty participants. Scaling that base into a market requires mainnet, paid contribution, and a value-accrual story that gives contributors a reason to stay.
Second, does the bandwidth-reduction work hold up at frontier scale? The bandwidth-reduction story rests on OpenDiLoCo’s 2,000x figure. The trick has to be re-proven in the presence of larger models, longer pre-training runs, and architectures the team hasn’t trained on yet. Each new training run extends the proof one configuration at a time.
Third, what is the realistic competitive position against centralized labs? Defensibility in Prime Intellect lies in open weights, community ownership, censorship resistance, and accessibility outside the existing capital base. This all must be served at a quality level that makes those properties worth paying for. The most realistic workloads for that slice are post-training, community-assembled fine-tuning datasets, and niche models the major labs don’t target.
INTELLECT-2 proved those workloads are reachable. The next training runs will scale to larger models, paid contributors, and live tokens, testing whether the network underneath can grow with them.